by Nicholas Carlini 2025-03-13
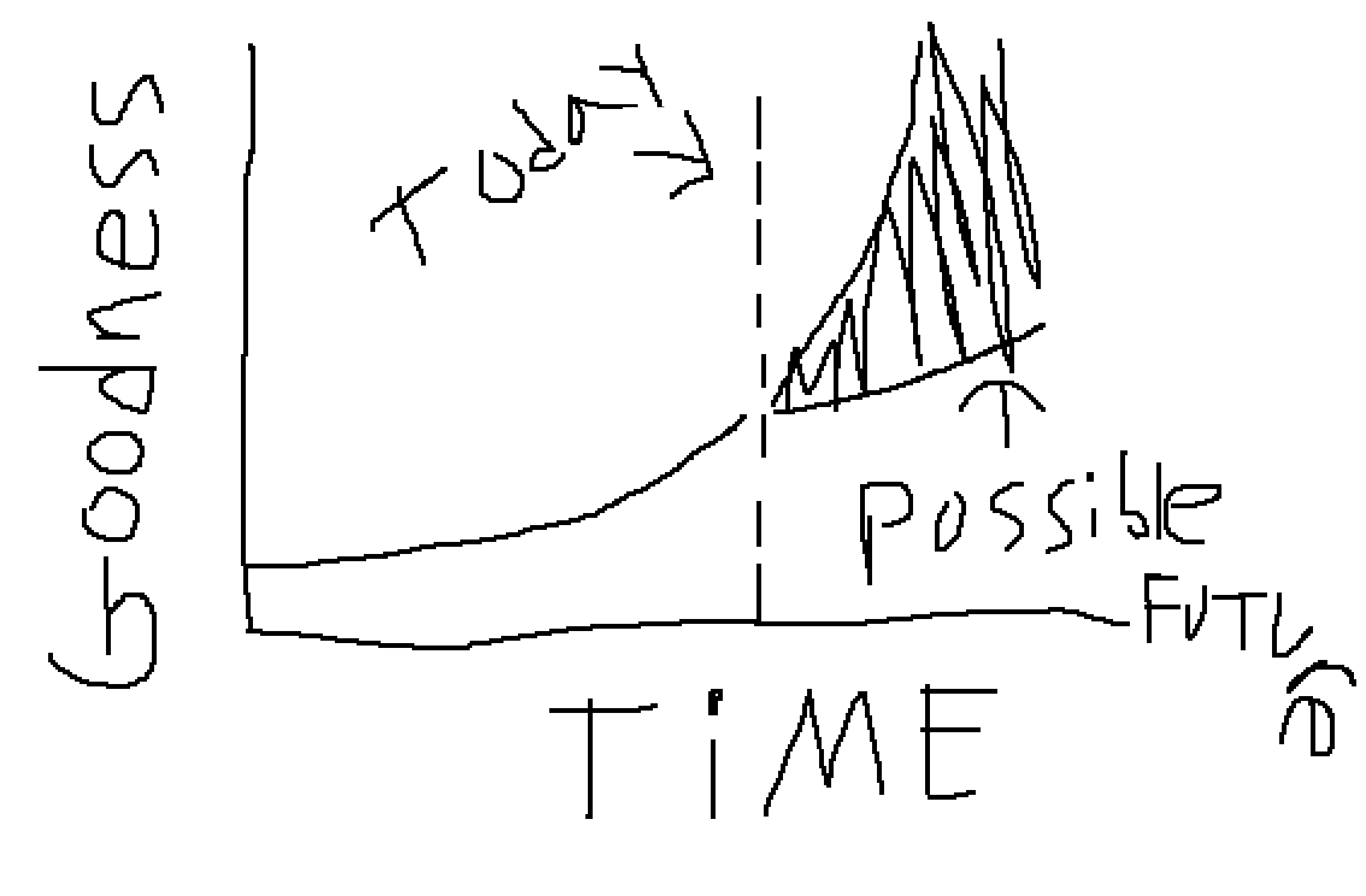
I have very wide error bars on the potential future of large language models, and I think you should too. Specifically, I wouldn't be surprised if, in three to five years, language models are capable of performing most (all?) cognitive economically-useful tasks beyond the level of human experts. And I also wouldn't be surprised if, in five years, the best models we have are better than the ones we have today, but only in “normal” ways where costs continue to decrease considerably and capabilities continue to get better but there's no fundamental paradigm shift that upends the world order. To deny the potential for either of these possibilities seems to me to be a mistake. (Importantly, I'm not claiming either extreme is likely, I expect things to be somewhere in the middle, but I believe these are both possibilities that you should take seriously.)
Why do I think both of these futures are possible?
- On one hand, maybe we're just getting started with this whole language model thing. In five years we've gone from LLMs that could barely string together a coherent paragraph, to LLMs that can solve math problems at the level of early PhD students, and write code at the level of expert competitive programmers. Benchmarks have been falling as fast as we can create them, and exponentials grow so much faster than we realize---so who knows what another five years could even bring?
- On the other hand, maybe we're going to continue seeing a period of growth for a little longer, but after a year or two, we'll reach a point where we max out the capabilities of large language models. Maybe the available training data runs out, or we can't get enough compute, or the funding dries up, or transformer capabilities just have a hard limit in the same way that SVMs did in the past. After that, maybe LLMs get cheaper and faster, but they don't continue on the same exponential we're on here. Still, current models are already capable enough that LLMs in five years will likely get integrated into more products, and this will be a Big Deal. But it won't change the future of humanity.
Depending on who you are and what you've read about "AI" language models recently, it's highly likely that you disagree with me wildly on one of these two opinions. Put me in a room with your average SF alignment researcher and I'm the naysayer who doesn't "feel the AGI". But put me in a room with the average programmer and I'm the crazy one who thinks there's a good chance that LLMs will be strictly better at programming than they are in short order.
So in this post I'll try to do exactly one thing, and argue that “you should have wide margins of error”. I'm not going to do this by trying to make deeply technical arguments, because I get the feeling that most people decide what they want to believe, and then go looking for the evidence that supports their conclusion. So here I want to try to give you the intuition for why I think you should have wide error bars. From there feel free to go find the technical arguments that justify whichever side you want to believe.
(This is part 2.75 in a 3 part series where I decided to finally write down my thoughts on AI. In part 1 I talked about how I use large language models (what everyone means when they say "AI"). Then, in part 2 I made a simple application where you can forecast and track your beliefs about the future. Last time (in part 2.5....) I discussed other peoples' predictions about the future of LLMs. And so this time, in part 2.75, I'll talk about where I see this all going in the future. Finally, in part 3 I'll talk about what I'm worried about, what I'm not, and where I'm uncertain.)
Humility
I want to start out by talking about humility, in the sense that it is important to understand that you, in fact, might not be an infalible predictor of the future. Just because you believed (and widely stated) something a few years ago does not mean you must continue to believe this same fact.
Specifically: it is entirely okay to say “I was wrong. I have changed my mind.” Watch: I'll show you.
I was wrong. I have changed my mind. Going back and revisiting my prior talks from (roughly) 2018 to 2021 is a wonderful exercise in humility for me: I was clearly and obviously wrong about the future potential of large language models. This is because I was very much in the camp of "these models are fun toys to play around with, but have no practical real world utility". I studied them as toy research objects which might be useful for individual specific tasks like sentiment analysis or translation, but never as general purpose technologies. I continued to believe this even after the release of GPT-2, GPT-3, and PaLM---three language models that were groundbreaking in their time. “Oh, that 540 billion parameter model can explain jokes? That's cute; tell me when it can do something useful.”
But as I discussed at length in the first post, language models have now become extremely useful to me in my work. I was very wrong about the future potential of these models five years ago. And I am willing to admit I may be wrong in the future.
The world today changes faster than ever before; and so something that used to be true thirty, ten, or even two years ago may not be true any more today. It's only natural to want to reject ideas because they are new. Changing your mind about something is uncomfortable, especially when it's something that you had a strong belief in previously.
But as "technologists", I think that's what makes us successful: our ability to understand that the future might actually look different from the past, and that what previously seemed impossible might actually be possible. So, as I said above, depending on who you are and what you've read in the past, you may read this post and think I'm obviously wrong. Maybe I am. But maybe you are.
Clear limits don't exist
There's a simple reason that you should have wide margins of error. The current approach of LLMs is working now, it has not shown signs of slowing down, and so as I say above, it's entirely possible that it will continue to work. But it's also possible something breaks, something is harder than we thought, and the whole thing falls apart. Let me now talk about this in more detail.
The challenges of upper bounding capability
Probably the most common critique people give for why this whole LLM thing won't work out is a statement of the form: yes these models are getting better, but they have some fundamental limitation in how good they can get. If you're trying to get to the moon, you can get closer by building increasingly tall towers, but this will only get you so far. So then you take an entirely new approach, and make a hot air balloon. This can go so much higher than a tower! But it still can't get you to the moon. That's just not how things work. Eventually you realize that rockets are a thing, and they can actually get you to space.
Maybe AI is like this. Initially we thought simple machine learning methods would get you to AI; famously, in the 1970s Marvin Minsky said "In from three to eight years we will have a machine with the general intelligence of an average human being. I mean a machine that will be able to read Shakespeare, grease a car, play office politics, tell a joke, have a fight." Obviously this did not come to pass. Then we decided maybe the correct approach to AI is symbolic reasoning, and we built expert systems. Those also went nowhere. Who is to say that this same thing won't happen with deep neural networks?
I used to hold this belief, too.
The problem with the argument is that you can point to actual physical laws that explain why towers and hot air balloons can't get you to the moon. No such physical law exists for LLMs: instead, we have a sequence of arguments that people make of the form “here is some clear line that I think LLMs won't be able to cross for [reasons]”.
But these lines aren't actually laws of nature; they're more like assumptions that we've made about the world. Just six months ago people were talking about how LLMs are plateauing and we won't see anything better than GPT-4, and then we get RL with o1/o3 and r1 showing us that models can train on their own outputs to self-improve at least one step forward. So, people say, “okay well maybe that was the wrong line, but this new line I'm drawing is the real limit”. And maybe this time they'll be right. But maybe not.
So: if you currently believe that there is some fundamental limit to how good LLMs can get because there's some line that they can't cross, here's an exercize for you: pre-commit now to a specific line that you think explains a fundamental limit of LLMs. Something that, if crossed, would make you say “okay, I was wrong. Maybe it's not so easy to draw a clear bright line.”
This is what I did roughly in 2021 when it started to become clear to other people that this LLM thing was maybe a big deal. I didn't believe in the applications of LLMs because it seemed obvious to me that training on next token prediction wasn't going to be able to give you coherent responses across more than a few paragraphs. And I was fairly certain that next-token prediction (1) wouldn't get the model to build some kind of internal world model, and therefore (2) would cap out at just being some simple statistical next token predictor.
But then it turned out that LLMs got far, far more powerful than I thought they ever would. They've blown past any prior clear line I might have drawn in the sand.
And so, for me, now, it basically seemed like there is no bright line I can draw. It's more of a continuous gradual spectrum of difficulty, and I think LLMs have the potential to be able to continue to scale. But let me give you a few candidate lines that you might believe that, even if we can't pin a physical law down to explain why they're impossible, you might think are fundamental limits to LLMs. If you don't like these, maybe you can come up with your own. But I think if you have this belief, you should be able to articulate what your next line is, and then be willing to change your mind if we cross it. So let's try potential lines; maybe you believe ...
- LLMs can't generalize from a small amount of data; and so they would never be able to learn to play a new board game just by reading the rules or learn a new programming language just by reading the manual. (Note: this is already partly wrong. The recent o3 model shows it can solve ARC-AGI with just n<4 examples, albeit in a very expensive maner.)
- LLMs can only generate output that's less "intelligent" than the training data; and so they could never train on a dataset of low-quality text and then produce something obviously better than the best training example it was trained on. (Note: this is also already partly wrong. Research on chess has shown LLMs trained on human games up to a low skill level can then play at a higher skill level than any game they trained on.)
- LLMs have finite computational depth; and so they will never be able to solve problems that require the ability to reason more than a fixed number of steps ahead. (Note: this is also already partly wrong. I talk about this later, but chain of thought shows that LLMs can spend many tokens preparing an answer instead of just one.)
- LLMs can't generate new knowledge; and so they'll only ever be able to do things we know how to do today. Putting aside for the moment that most "new" things are just obtained by taking ideas from some other area and applying them in a different way, this is maybe the last barrier that I can think of that we maybe won't be able to cross. But it's also one that's really hard to write down a formal statement of, because of the fact that "new" usually does just mean "applying old ideas to different problems".
- [come up with your own line here]
... but who has the burden of proof?
If I claim that it is possible to build a magic box that can do anything a human can only better, then I have the burden of proof to show that this is possible. I can't say “well, you can't prove that it's impossible!”.
And I think that most people, even the AGI-is-coming-soon crowd, would believe that we have a long way to go from where LLMs are to now until they reach the point that they can become fully general AI systems. As a result, there are likely to be many challenges we will have to cross to get there. Who says that, just because we've crossed a few lines on the way, there aren't even larger hurdles ahead?
There are so many things that could make it hard to continue to scale up LLMs. We could run out of training data; we could run out of compute; it could take more compute than we expect to get the next level of performance; it could be possible to reach this level eventually but funding dries up and so we don't reach it soon; there could be some hard capability limit to the non-symbolic LLMs we're working with; there could be some soft capability limit that requires a new architecture or training method. Recently in the past 6 months we've seen it's possible to train models with reinforcement learning, but maybe this was just a one-off trick that won't continue to work. Maybe we'll find a few more tricks like this, but each next trick is harder to find than the last.
Every time in the past that we've tried to scale up a technology, we've run into problems that we had to address. Computers initially ran on vacuum tubes, and it was clear (because of physics) that you can't possibly build a computer with, say, a million vacuum tubes per square inch. It's just not possible. But then we invented transistors, which basically completely solved this problem. Transistors, too, will run into physical limits (if they haven't already) and we'll have to come up with something new.
We've started to see signs of this just in the last few weeks. GPT-4.5, OpenAI's latest language model, performs only slightly better than GPT-4 on esentially every benchmark that we can measure. Sure, maybe it has better "vibes" or something, but this is not something that we can actually quantitatively measure. Even the people at OpenAI who trained the model wrote in the technical report that “GPT-4.5 is not a frontier model.” and don't seem to be that happy with the result.
Maybe this is going to be the way things are from now on. We'll spend 10 times as much money training a model that costs 10 times as much to serve and the fruits of our labor will be a model that's only slightly better than the last one.
But it's important to accept that there is no clear physical law that explains why this has to be the case in the same way there are physical laws that limit the scaling of how small you can make a vacuum tube.
And so this is where I actually stand today. I still believe there is something fundamental that will get in the way of our ability to build LLMs that grow exponentially in capability. But I will freely admit to you now that I have no earthly idea what that limitation will be. I have no evidence that this line exists, other than to make some form of vague argument that when you try and scale something across many orders of magnitude, you'll probably run into problems you didn't see coming.
And all of the simple lines that people have drawn in the past don't seem like fundamental limitations to me, at least for the next few years. And so I'm actually not sure who has the burden of proof here: maybe, once someone has shown scaling trends across six orders of magnitude and then claims it will continue for another three, I'm the one who has to explain why their trend is wrong?
And so this explains my wide margins of error. AGI in three years? Possible. Capability plateau for the next five years? Also possible.
Two hypothetical stories
Future #1: The Case for Exponential Growth
Every once and a while, we stumble across a technology is special, and enables its own improvement.
Maybe the best and most recent example of this is Moore's Law. You build better computers, those computers enable you to develop better science and engineering tools, and those tools enable you to build better computers. The shortest path to 3nm manufacturing is through 5nm manufacturing. If you were someone in the 70s and wanted to make a 3nm process node, you couldn't do that without having first built (something close to) a 5nm node.
But there have been other examples of this kind of technology in the past. If you want to make high precision machinery, it's really helpful to have (slightly less high precision) machinery with which to make your higher precision machinery. Each machine you make allows you to design parts that have a higher degree of precision than the last. A machine that has an accuracy only to 1cm just can't be used to build a machine that has an accuracy of 1 nanometer; you use the first machine to build a second more accurate machine, and so on.
Maybe machine learning is a technology that acts like this. Some people have long hypothesized that we'll reach some kind of "singularity" point where we build a machine that improves itself by, for example, rewriting it's own code from scratch and inventing new and better algorithms. So far, the major driver of progress in machine learning has been by spending more money and using more compute to train larger models. But if we ever got to the point where we used our current advances in LLMs to directly drive the development of better LLMs, then we might see an extremely fast rate of progress. This is, I still think, somewhat unlikely. But given that LLMs today can already basically write some nonzero amount of code that enables better LLMs (e.g., aider is mostly written by aider, and DeepSeek is now writing WASM SIMD kernels to improve DeepSeek performance), we shouldn't dismiss this possibility out of hand.
But also: I don't think we even need to have models that do clever research and write their own code that makes future versions of themselves better. You could just end up in a world where language models help improve their own datasets and insodoing make the next version of themselves better. And this could happen well before we get the ability of models to write their own code. In fact, it's very possible that we are already there today but just don't realize it yet. The recent advances in reinforcement learning have shown almost exactly this.
Specifically: how do you get DeepSeek r1 (the language model that shocked the stock market in late January)? You take DeepSeek v3, and ask it to solve a bunch of hard problems, and when it gets the answers right, you train it to do more of that and less of whatever it did when it got the answers wrong. The idea here is actually really simple, and it works surprisingly well.
To some extent this shouldn't be that surprising. We've known forever that you can take a model that plays games (e.g., Go) and have it play against itself in order to make a really high quality Go playing model. This is how we got AlphaZero. There's not much fundamentally different between this and what we're doing now with DeepSeek r1.
And so I think there is a very real possibility that the reason we end up with (much) more advanced language models in the future is because we use these models themselves to help us build better models, either by curating a better dataset, or just by directly writing their own code better. And if this works out, then this shows a pretty clear path towards some very advanced language models in the near future.
If this is the future that we're headed towards, then we should expect to see clear signs of this happening in the near future. If, within the next year or two, we don't see a research paper or product that shows how to train the next generation of language models using the outputs of the current generation, then I'd be much more skeptical of this future.
Future #2: The Case for a Plateau
When NASA was created in 1958, the USSR had only just launched the Sputnik satellites into space. But within three years, in 1961, NASA managed to launch a person to space. And by the end of the decade, had landed people on the moon. Fifty years on ... and we still haven't been back. To put this in perspective, people last walked on the moon closer to the end of World War 1 than today.
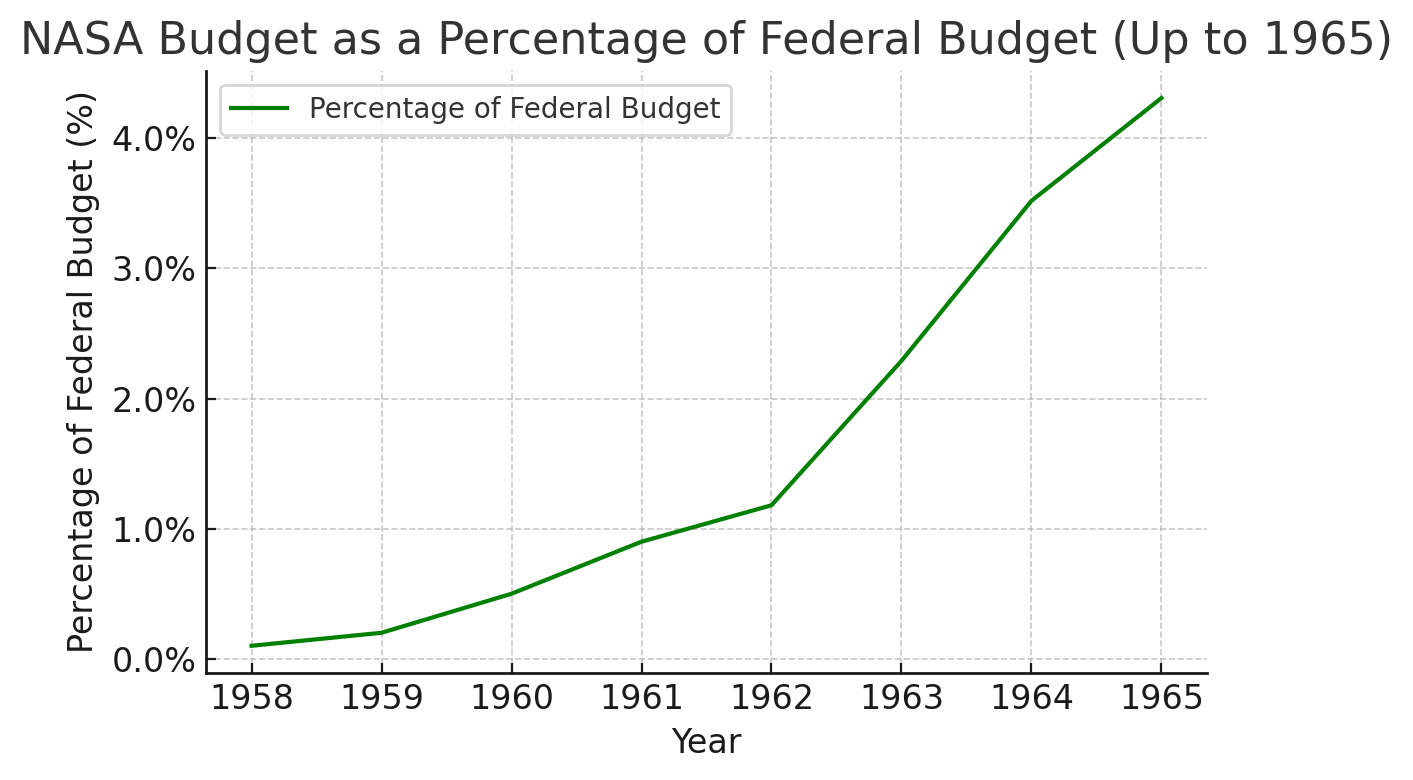
But if you, an intelligent forward-looking person in the 1960s, were to look at this rate of progress, you might reasonably expect that in a few years we'll have a human base on the moon, people walking on mars, and in short order be colonizing the stars. You might even get so excited about things that your version of the future you imagine our guiding mission would be to explore strange new worlds; to seek out new life and new civilizations; to boldly go where no one has gone before. Because, from your perspective here today, that's the direction things are headed.
But looking back with the benefit of hindsight, you can begin to understand why none of this came to pass: When NASA was created in 1958, its funding accounted for 0.1% of the US government's federal budget. Over the course of the next three years its funding increased by a factor of 10, and then in the four years after that by another factor of 4.
Looking at the data up until this point, you can see how you might be extremely excited about the future of space travel. Obviously we're going to continue investing in this technology, and obviously we're going to continue to see the same kind of growth that we've seen in the past. What could possibly stop us?
What you don't know, and couldn't know, is that in just five more years the fraction of government spending on space travel would drop by a factor of two and would never recover. After putting twelve men on the moon between 1969 and 1972, five decades on we still haven't recreated this achievement.
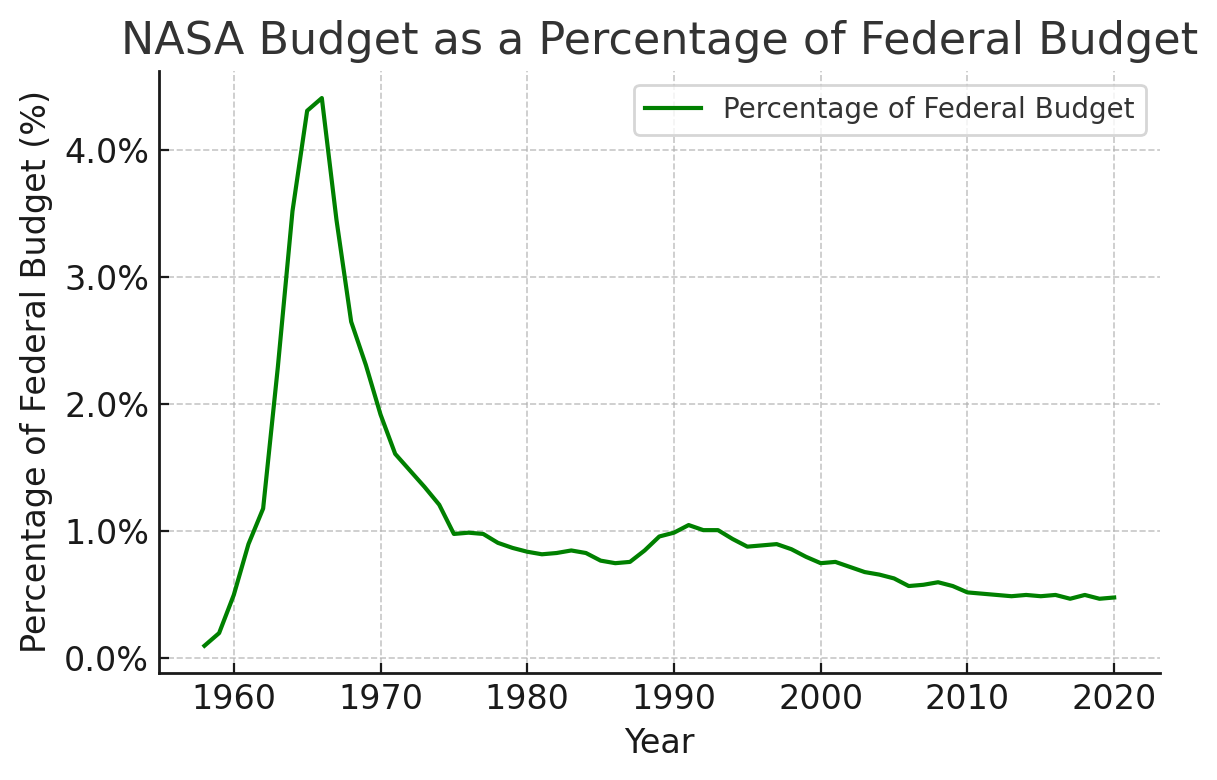
... which is not to say that the NASA program was a failure. Half of the modern world wouldn't work without satellites. I don't have nearly enough time now to talk about everything in our world today that depends on the discoveries we made in the space program.
But in the 1960s we were simply not technologically advanced enough to be able to sustain the kind of growth that we were seeing in the space program: we were achieving (amazing!) feats through brute force, and brute force only gets you so far.
To compound on top of this, putting people on the moon does not make you money directly. There is no intrinsic value to this. And so while you might be able to convince investors (the citizens of the US) to fund your program for some amount of time, after a while they will start to ask "what tangible benefits are we getting from this?"
Now let's talk about language models. One of the key drivers of progress in LLMs has been our ability to pump more dollars, and more data, into these training runs. As an example: the most expensive LLM training run in 2019 was GPT-2, for a cost of a few tens of thousands of dollars. Just five years later, and we're now spending a few tens of millions of dollars on the largest training runs. These LLMs are an impressive technology, but we're basically getting there by brute force.
And there are already signs that this straight brute force approach might fizzle out. I mentioned above the example of GPT-4.5. Even OpenAI isn't sure what exact value of this model has. Anthropic, for their part, has still not released Claude 3.5 Opus (their largest model) after stating publicly that they would probably release it in late 2024. Maybe it's just not that impressive? (Please note: I will be joining Anthropic next week, but at this moment, am not yet employed by them. I have no inside information whatsoever, and so for a few more days I can still wildly speculate however I'd like.)
Now it's still early, and generalizing from just a few data points is always going to be dangerous, but you'd have to be remarkably optimistic to think that there's absolutely no chance this trend will continue.
In particular, I think one of the most likely ways this happens is if companies continue to run their incredibly inane ad campaigns talking about how AI can help ... your daughter write a letter to their favorite olympic athlete? (Who ever thought that was a good idea??) If the public starts to get fed up with the constant hype and lack of any real benefits, then I can definitely see investors losing faith that the next generation of models and funding rounds will dry up as a result. Even if these models would have gotten us to AGI or whatever that means, we might not find out for a long while because we just couldn't sustain the growth because we poisoned the well with our hype.
So the key question in my mind is this: will we continue to train LLMs in this brute-force approach? If so, we'll continue to see progress only as long as we're willing to invest more resources. As soon as our appetite for that dries up, so too will progress. Maybe this happens because of another recession, or maybe it happens because investors just get fed up with the constant hype and lack of tangible benefits, or maybe the next generation of models just fails to deliver value and the investors lose faith that the one after that will be any better.
If this is the future we're headed towards, then I would expect to see some scaling problems and diminishing returns emerge in the next few years. More models like GPT-4.5 are released that are incremental improvements, and post-training doesn't considerably improve them compared to their smaller predecessors. On the money side, maybe funding dries up in the next year or two; current funding rounds for the likes of OpenAI and Anthropic are in the billions to tens of billions of dollars. The next rounds will be in the tens to hundreds of billions of dollars. I expect these to happen whether or not LLMs continue to show massive improvements. But I don't think there is any way we will see hundreds of billions to trillions of dollars in funding without there being clear and obvious benefits to society (and dollars in investors pockets).
1.3: Common Complaints (I used to believe)
The purpose of this article is to argue that both the extreme AI-gets-scary-good and AI-stalls-out events are possible. But since most of the people I interact with on a day-to-day basis argue that the latter is more likely, and because this is the belief I used to hold, I want to spend some time arguing against it.
Because I get the sense that some people who argue that LLMs will stall out have an implicit belief that it actually is impossible for them to get (a lot) better. In their (and my past) mind, there is some fundamental capability limit of our current LLMs. So here I now want to try and argue against this belief, because I used to hold many of these beliefs myself.
"LLMs can only perform bounded computation"
Many people today argue that because machine learning models perform a finite number of operations per output, they are fundamentally limited in their capabilities to only those tasks that can be solved with a finite number of operations. This means that they won't be able to solve multi-step reasoning tasks, and will only ever be able to perform simple pattern matching.
But this just isn't true any more. Yes: language models only perform a finite computation for each token they output. But they don't have to solve each problem in exactly one step. If you just ask models to think step-by-step, you can break down complex problems into a series of simple steps.
The recent "reasoning" models like OpenAI's o1/o3 and DeepSeek's r1 are a good example of this, having been explicitly trained to output several hundred or thousand tokens thinking through a problem step-by-step before outputting an answer.
And while yes, these models are stil limited in that they can only process a few hundred thousand tokens at the same time, this limit is not fundamental and is sufficiently large that I don't think it matters much. In the same way that your computer technically is not a Turing machine because it has finite memory and so can not perform unbounded computation, LLMs aren't technically fully general either but this finite-capacity argument is basically irrelevant in practice.
"LLMs can't solve new tasks"
First let's make sure we agree on something: there is an important difference between “can not” and “currently do not”.
Researchers who study language models have a, shall we say, poor track record of making predictions about things language models could never do only to be proven wrong a few years later. (Or, in several cases, to have been proven wrong by models that already existed at the time.)
Arguing that LLMs can't solve new tasks is a bold claim. Even if we presume that LLMs will never be able to solve tasks that have been already represented in the training data, there's a vast quantity of novel research ideas that just ask what happens if you take two ideas from two different fields and combine them.
Let's even look at my research for examples of this. Some of my most interesting recent work has basically just asked “what happens if you apply techniques from cryptanalysis to language models?”, or “what happens if you consider the network security implications of training data curation?”. Neither of these papers are particularly groundbreaking, the math isn't particularly hard. You just have to have a fairly vast knowledge of the literature---something that current models are already quite good at.
"Let's all laugh as this model gets this trivial thing wrong"
This is a particularly frustrating argument. Every once and a while someone will post a tweet or a blog post showing that some model can't, e.g., count the number of 'r's in the word strawberry, or that it thinks the mathematical expression 9.11 > 9.7 is true. But you should never evaluate someone (or something) based on the cases where it performs worst. I don't complain that my calculator is a terrible hammer. I don't try to use my soldering iron to make toast. You shouldn't use your LLM when obviously something else would be better.
Separately, how we moved from "wow you mean the model can recognize birds?!" to "haha the model is so dumb, look at this one example of a task I made up the model can't solve!" I will never understand.
Whereas previously we were amazed when models could solve the exact task we set out for them to solve, today we're upset when they can't solve a task we didn't even train them to solve. A much more substantive critique would be if you could propose a set of simple tasks that you believed no model could ever solve; unfortunately though, every time someone has done this in the past, we've had to wait just a few months for someone to come along and solve that dataset too.
If you're someone who believes you have a trivial task that future models won't be able to trivially solve, I would love to write a paper with you where you lay out your simple set of problems that you're confident no model could solve in the near future that humans find trivial, and then we'll wait a year or two, and see what happens. My guess (say, 70% probability) is the LLMs will win, but I'm happy to be proven wrong, and indeed think it's entirely possible. (That's the purpose of this entire article!)
"It doesn't understand!"
Do we ask if Stockfish, the world's best chess engine, "understands" chess? No. We do not. Whether or not Stockfish “understands” chess is irrelevant; all that matters is whether or not it can play chess at a higher level than any human living or dead. And here we have extensive evidence that it can. So why should we care if it “understands” chess?
By the same vein, I don't think we should really care that much if the models we have today “understand” language. Not only is this question not even well defined (what does it even mean to “understand”language?), whether or not they understand language is irrelevant when evaluating their utility. All that matters is whether or not they perform useful tasks.
And maybe even still, maybe you look at these models and say they're not that impressive. And so therefore they're clearly not understanding. If you make arguments like this, as I did previously, I would encourage you to pause for a moment and think: what is the minimum demo that would impress you? It's important that it's a minimum demo. Anyone obviously would be impressed by a model that could resolve P =? NP. But are you sure there's nothing less than that you'd be impressed by? And then go ahead and write that down. In a year or two, come back and take a look at what you wrote: have we solved your problem?
The history of machine learning is littered with people who said that LLMs would never be able to solve a given problem, only for some model to come along and solve exactly that problem in a few months. So I think it would be worth you trying this too. What is the minimum demo that would convince you that some amount of understanding is present?
(Now: maybe you're someone who points out that it's pretty dangerous that we'd rely on models to perform tasks for us if we don't understand how or why they work. And I agree with you! This is exceptionally dangerous. That's literally the focus of my entire research agenda. And in the next post I'll talk about this at length. But “that thing could be dangerous” is not a refutation of the claim “that thing could become very capable in many settings”.)
"But they're so data inefficient!"
Language models need to be trained on a lot of data in order to be useful. Many orders of magnitude more data than a human would need to learn the same task. This is true.
Why does this matter, though? There's relatively good evidence that, while we might run out of training data at some point, it's not going to be in the next few years. (And, recall, the next few years is all that I'm arguing about in this post.) So while, sure, it would be great if language models didn't require so much data to learn to solve each new task, this is not a fundamental limitation that will prevent them from getting better in the next few years.
It would be fantastic if we could build models that could learn from a fewer examples, but I don't think that's a fundamental limitation that will prevent us from reaching very high levels of capability in the next few years.
"They can't be human level!"
Can a computer ever be "human level"? Even defining this is basically impossible: human level at what? Playing a game of chess? Like a human would, or just playing better than a human? Feeling sorry for your opponent? I think this question is basically unanswerable, and isn't something worth discussing for us computer scientists. Human Level isn't even something that can be measured on a single axis, so maybe let's just not talk about it?
The reason I think it's particularly unhelpful to talk about "human level" is that Looking back on the past, once upon a time we thought playing chess was a uniquely human ability. Then we wrote papers about how to make computers play chess, and better than any human. But clearly these chess-playing programs weren't generally intelligent.
Then, maybe, we thought that if we had a program that could write poetry or talk about history, that program would have to be human-level and general intelligent. Except now we have language models that can write poetry and talk about history, but they're obviously not generally intelligent.
So instead of philosophizing about what it means to be human-level, let's maybe instead ask if they can accomplish specific useful tasks. And this is independent of whether or not it can be considered "human level."
"But they make things up!"
I understand people's complaints about models making things up. Ideally, we wouldn't want models to do this. While writing this post, even, Claude would consistently make up spelling and grammar errors in this post. Everyone agrees that would be better if they didn't make these things up. But, this limitation doesn't actually prevent us from making practical use of these models. You know why? Because we're already used to the fact that things can be wrong on the internet! No one expects every Stack Overflow answer or Reddit post to be perfectly accurate. When someone argues we can't use models because "the answer might not be right," I just don't understand, because anything else we read online could be wrong too!
But suppose that making things up was a complete dealbreaker for you. That's fine too, there are a huge number of applications where you can actually check for correctness. This is particularly true in programming, the domain I care about most. You can often check if you got the right answer by just running the code and testing it. If a model hallucinates an API that doesn't exist or writes buggy code, it's not a major issue---the model could just run the code and verify the results. If it fails because the API doesn't exist, it can identify that and use the correct API instead.
This isn't to say I have no concerns about the risks here---I actually have REALLY BIG CONCERNS ABOUT THIS. But this article is not about the risks of what might happen if we deploy these models widely, it's about whether or not we'll be able to do that in the first place. But as a brief teaser, my main worry is that we'll have models that hallucinate infrequently enough that companies will put them in charge of important decisions because it's usually fine. And then, whoops!, the model made a mistake and caused some catastrophic failure. This would be very bad, and I'll have a few thousand words to say about it in a month or so.
Conclusion
LLMs are clearly useful today, and I believe they will be even better tomorrow. But I do not know how long this trend will hold.
Put differently: I think there is a very real probability that in five years we look back at the LLM hype of 2023-2025, we see it like we now see the Internet bubble of 1998-2000 (that is: a very new technology that will eventually have an impact, but that was overhyped in the short term). But I also think there is also a very real probability that, in the future, we will look back at the mid 2020s as the beginning of a new era, and when we list the most important inventions of humanity we include “AI” in the same sentence as the wheel or the printing press.
What I hope that I've successfully argued in this article is that you should be willing to entertain that either of these two futures is possible. Neither is guaranteed, but neither is unquestionably impossible.
In some small number of years we'll have an answer to this question. And it will look obvious, in retrospect, what the answer was. We'll say "Of course scaling continued for another five years, Moore's law held, why wouldn't we expect the AI equivalent to hold??" or we'll say "No exponential continues forever, isn't it obvious that LLMs plateaued??" And the half of the people who were unreasonably confident but ended up right will have the ability to say "I told you so". I just hope that we remember that predicting the future is hard, and we honestly can't know exactly how this is going to go.
So over the next few years, I'd encourage you to keep an open mind and be willing to see the world as it is, and not as you want it to be. We're going to learn a lot, things are going to change a lot, and so we need to be willing to accept what comes to pass, and not reject something just because it's not what we expected.
There's also an RSS Feed if that's more of your thing.