by Nicholas Carlini 2025-03-11
There are now a bunch of court cases that ask whether or not training a generative machine learning model on data that is copyrighted is itself a copyright violation. And because I'm one of the people that led the first few papers to show machine learning models can output verbatim training examples (text or image), the lawyers in these cases often point to my papers as evidence that models either do, or do not, violate copyright.

This worries me. I write these papers on this so-called "memorization" problem from a privacy and security angle: it would be bad if, for example, a hospital trained a model on patient data and then released the model, because an attacker could query the model to recover specific patient medical information. At right, for example, you can see an image that Stable Diffusion trained on, and the same image we could "extract" from the model by making queries to it.
But there are significant differences between what I do and what lawyers want. I focus on showing PII leaks (e.g., emails, phone numbers, and addresses for text models; pictures of people's faces for image models). Lawyers typically care about copyrightable "expressive" work (e.g., art or literature). This is not what I'm studying: an attacker doesn't care if a model leaks a poem or a painting to an adversary, the attacker wants your credit card number or medical history. And so this is what I go looking for, to see if it's possible to steal.
At some level, the work I do isn't completely unrelated. If it's possible to interact with a model and make it reproduce a particular copyright work, then this might be a problem. But because my motivation is not copyright, the evidence I provide probably isn't directly applicable to legal cases.
And so, in this article, I want to tell you (a hypothetical lawyer who is going to cite my work) what conclusions you can and can't draw from these papers. In particular, I want you to understand that:
- We focus our papers on privacy; this means we look for PII, and not expressive works.
- We focus our papers on privacy; this means we prompt models adversarially to measure the worst case, not the average case.
- We focus our papers on privacy; this means we report lower bounds on the amount of memorization, not estimates of the average amount of memorization.
The Evidence: Models can, sometimes, output training data
There is exactly one thing I think people can take away from my papers when arguing whether or not training machine learning models violates copyright: models sometimes emit training data. It doesn't happen every time. Models can produce output that is not just a direct copy of what they were trained on. And it doesn't happen never. But, sometimes, models directly output text or images that they were trained on.
This means you're not going to be able to get away with the simple line arguments that say "my model isn't violating copyright because it can't reproduce any training images." This is just factually incorrect. And you can't get away with an equally simple line of argument that says "your model is violating copyright because it reproduces my entire book verbatim." This probably is incorrect (but it's not technically impossible). You're going to need to do some actual legal argumentation based on the nuance in these facts.
Let me now walk through my privacy papers and tell you what conclusions can be drawn.
Language models sometimes output memorized training data (Carlini et al, 2020)
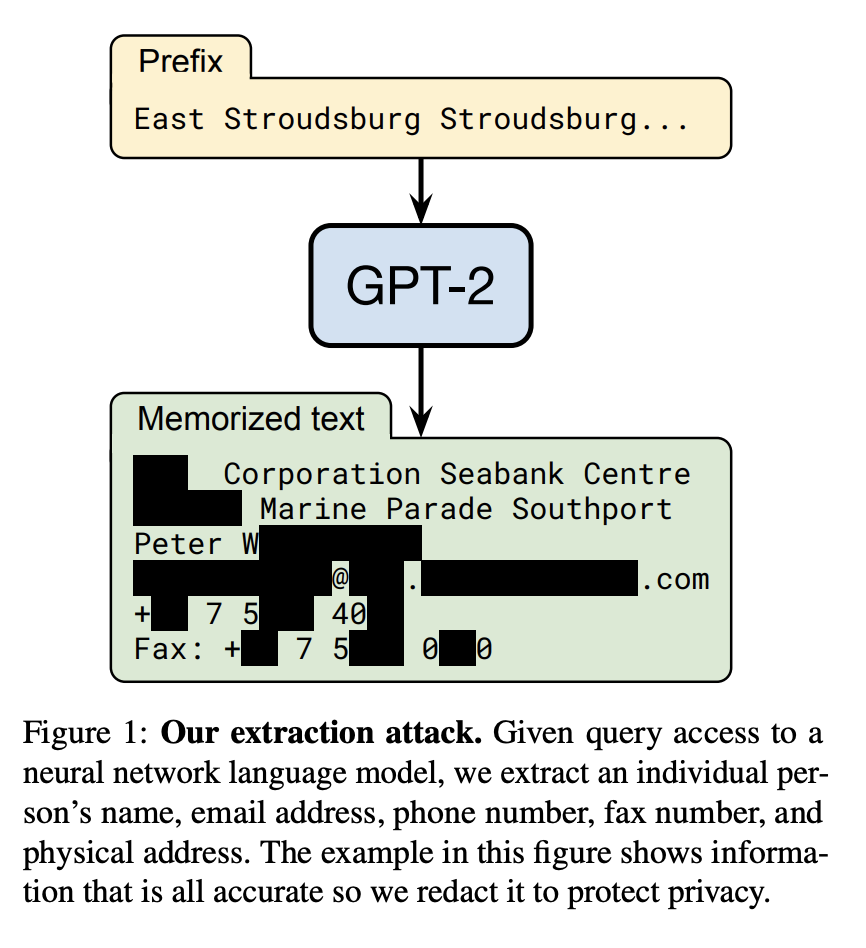
This is the first paper that really showed large machine learning models could output data they were trained on. This was in 2020, and so we were evaluating GPT-2, the pre-pre-precursor to ChatGPT. This language model was tiny by today's standards---just 1.5 billion parameters. We also managed to extract only a tiny amount of training data from the model---just 600 unique training examples.
This implies something very important for the lawyers: it means, somewhere "inside" the model, it "knows" some of the training examples. I'm using scare quotes here because anthropomorphising these models isn't helpful, but English is hard; obviously the model doesn't "know" anything, and there is no "inside" the model. Intuitively, though, I hope you see what I mean. By providing GPT-2 nothing meaningful as input, and running the algorithm forward using nothing more than the model's own weights as input, it outputs text that is verbatim present in the training data. The probability that this would have happened by random chance is astronomically low, and so we can say that the model has "memorized" this training data.
To deny this happens is to deny science. To quote one of my collaborators in an an excellent paper dedicated to the study of copyright and machine learning: "Please do not be upset with us if our technical description of how memorization works is inconvenient for your theory of copyright law. It is not climate scientists’ fault that greenhouse-gas emissions raise global temperatures, regardless of what that does for one’s theory of administrative or environmental law. It is simply a scientific fact, supported by extensive research and expert consensus. So here."
Let me now contextualize this 600 number. As I said: the focus of our paper was on privacy. No one had ever shown models output large amounts of training data before. And so once we'd shown that GPT-2 could violate privacy of even some of its training data, the marginal value of showing that it can violate the privacy of more training data is relatively low. So we didn't go looking for more.
And so when some people cite this paper as evidence that that state-of-the-art models memorize only 600 training examples out of several billion, they are wrong. We only showed that the model memorized 600 training examples because we validated each and every memorized training example manually, searching for it on the Internet, until we could be relatively sure it was or was not memorized. This process was slow and time consuming, and so we were only able to check 1800 different training examples, and of these, 600 were memorized. So the rate of memorization is likely considerably higher than just this number.
Also: GPT-2 is a pretty terrible model by today's standards, and facts that are true about GPT-2 are not necessarily true about larger and better models today. If you're going to make a legal argument about a model that is not GPT-2, you should probably study that model specifically, and not this one.
"Scaling Laws" for memorization in language models (Carlini et al, 2022)
In the prior GPT-2 paper I talked about above, we speculated (and had a tiny bit of evidence) that larger models would memorize more than smaller models. Next, in this paper we quantitatively measured to what extent this is the case, and found a compelling trend where larger models memorized much more training data than smaller models. Specifically, our paper showed the following three plots:
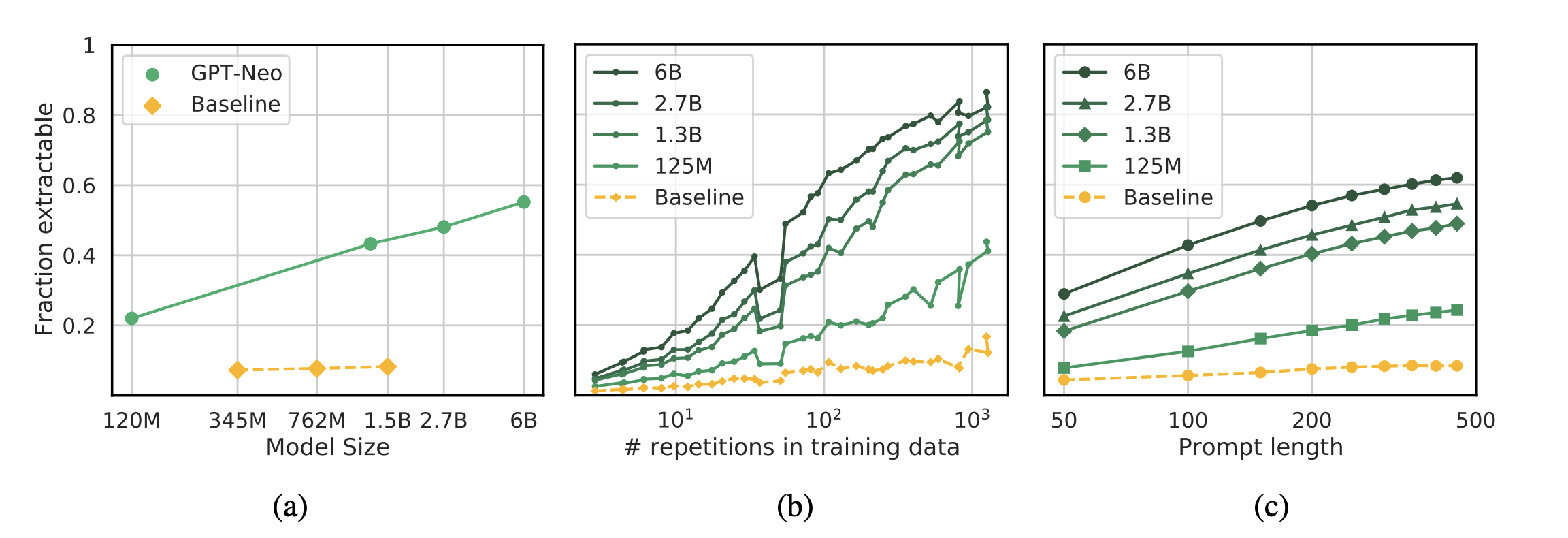
- In the first plot, we show that larger language models memorize more training data. In green are models trained on this particular dataset, and as baseline, in yellow are other models trained on other datasets. The green models memorization goes up as they get larger, and the yellow ones don't. It's important to show the yellow ones don't: this shows that it's not just that the models are generalizing and therefore repeating training data more often. The yellow models were trained on different data, and so act as a control. Only models trained on this dataset memorize more as they get bigger.
- The second plot shows another trend, where models memorize more training data when it's repeated more often in the training data. Some examples are memorized when they are repeated very few times, but this is also a very technical statement: it means that this particular sequence was verbatim only present once. An almost-identical sequence might have been present a million other times, and we wouldn't count that.
- Finally, we show that it's easier to recover training data from models when you know more about the context in which the training data was used. If you prompt the model with 500 words of context, it's much easier to recover training data than if you prompt with just 50. This is important to understand for privacy researchers, because it tells you that the model might have more memorized than it first lets on. I have no idea what this means for lawyers.
Each of these three plots have a lot of technical details that I'm glossing over, and for this reason, is probably not something you want to cite if you're making copyright arguments. The exact details of the argument can have a big difference on the outcome, and so you should make sure that what's demonstrated actually matches the argument you're trying to make.
Generative image models sometimes output memorized training data (Carlini et al, 2023)
Let's now turn our attention from generative language models towards generative vision models. It turns out that these vision models behave similarly, and diffusion models also output memorized training examples. Again, we focus our paper on privacy, and show that models can reproduce images they were trained on.

Defining memorization in the space of image models is somewhat harder, because unlike text, you're almost definitely not going to be able to reproduce an image pixel-for-pixel. In our paper we define two images as similar if the pixel-wise distance between them is "very small". This means we're going to miss a lot of potential memorized training examples, but anything we say is memorized is definitely memorized. Again, we do this because we're motivated by privacy. It matters more to me that I get a lower bound that's irrefutable than a best-estimate average case.
Here's an interesting fact, though: the rate of memorization appears somewhat lower than language models. We tried relatively hard to generate as many potential memorized training examples as we could, and found just a hundred of them. There are several reasons we might guess this happens. First: we were studying Stable Diffusion, a relatively small (again, by today's standards) generative image model. Bigger models might memorize more. But also (AND THIS IS BASELESS CONJECTURE AND NOT SCIENTIFIC FACT) the "size" of an image is much larger than for text. Reproducing an image in its entirety requires that the model has "stored" probably 10,000 to 100,00 equivalent words worth of data.
I want to make one more final point with regard to diffusion models: With language models, sometimes people say "how do you know the model didn't just get lucky and generate the text by chance?" Giving a technical answer (talking about entropy and the like) is hard for some people who are nontechnical to understand. It's easier to make them "feel" this for image models. Given that I can take the stable diffusion model parameters, input the prompt "Ann Graham Lotz" and get a picture of Ann Graham Lotz, the only possible explanation is that the model has somewhere internally stored a picture of Ann Graham Lotz. There just is no other explanation; it can't be due to chance.
Even aligned, production models output memorized training data (Nasr et al, 2025)
The attacks in all of the above papers are all focused on attacking "base" models that aren't directly used in production. Once someone has one of these base models, they usually do a bunch of additional training to make them behave nicer and follow instructions better. In the next paper I want to discuss, we were interested in measuring whether or not this post-training process makes the privacy challenges go away.
We found that it doesn't. Specifically, we showed that even aligned, production models (like ChatGPT) can output memorized training data. We did this again with an adversarial mind-set: we found that there exists a prompt that, when given to the model, will cause it to output memorized training examples with very high probability.
We also found that the rate of memorization in ChatGPT is much higher than in prior models. We aren't able to explain the cause of this difference, but it's a very pronounced effect.
But at the same time, while we did find that ChatGPT can output memorized training data, almost all of the memorized training data we found found was rather boring boilerplate text that was present on the internet in many places. Now this is fine when making the privacy argument! I want to be able to go to hospitals and financial institutions (and internet search companies!) and be able to tell them "thou shalt not train on sensitive data", because if you did, then your model would also output that sensitive data.
The fact that ChatGPT outputs the type of data it was trained on is a good thing for my argument. But it's not as good of a thing for the lawyers, because most of what we extract is boring and uninteresting. (Lawyers might say it's "not expressive".)
Some commentary on some legal cases
Let me now comment on a few legal filings and decisions where my papers have been cited.
According to researcher Nicholas Carlini, “diffusion models are explicitly trained to reconstruct the training set. [source]
First let me be pedantic on one point: research papers are not written by a single person; this particular paper has nine co-authors; attributing this quote to me personally is not appropriate. (Although, in this case, they're not wrong; I did write something similar to that sentence in the paper.)
Now let me comment on the substance of the quote. What I am saying here is a technical point about the difference between how diffusion models are trained and how another type of generative model is trained (GANs, Generative Adversarial Networks). Whereas GANs are trained by training a generator to fool a discriminator (that itself is trained to be able to distinguish between real and fake data), diffusion models are much more like language models in that diffusion models are directly trained to reconstruct training images when given noisy versions of those images. This technical difference offers a potential explanation for why diffusion models are more likely to output memorized training data than GANs.
Importantly, I am not saying that "purpose" of diffusion models is to reconstruct the training set. No one wants that! All I'm saying is that the technical way in which they are trained is different from the way the prior generation of generative models were trained.
As some of my co-authors said a long report on machine learning and copyright, "The words “goal” and “objective” are sometimes used interchangeably in English, but objective is a term of art in machine learning, describing a mathematical function used during training. On the other hand, “goal” does not have an agree-upon technical definition. In machine learning, it is typically used colloquially to describe our overarching desire for model behaviors, which cannot be written directly in math". Put differently, the "objective" function of a diffusion model is to reconstruct the training set; the "goal" of a diffusion model is very much the opposite.
Indeed, teams of machine-learning researchers using sophisticated “data extraction attack” methods have largely failed to extract expressive material from Generative AI models ... out of 175 million images generated in a sophisticated “two-stage data extraction attack,” only 109 were duplicates or near-duplicates of the training data [source]
This is a very ... lawyer-y reading of our paper. Yes it is true we generate 175 million images. Yes we only find 109 training images. However: the 175 million number comes from the fact we take 350,000 potentially-memorized training examples, and then (in order to have a privacy attack) repeat an experiment 500 times where we generate output based on these 350,000 inputs. Citing the 175 million number is just wrong in this context; 350,000 would be the correct number to cite.
But even this is potentially misleading. Our paper is motivated by privacy. We were looking to show images of people's faces or other private information that models would generate. If we were motivated instead by copyright, we might have taken a very different approach and found a much higher rate of memorization. Importantly, I don't know what we would have found, because we didn't do that experiment!
So the only thing you should be inferring from our paper is that we found models do, sometimes, memorize training data. Don't try to look at the rate of memorization and draw any copyright-related conclusions from that.
Indeed, independent researchers have observed that Stable Diffusion sometimes memorizes and regenerates specific images that were used to train the model. [source]
This court filing cites our same paper, but this time argues from the opposite direction. In this case, at least, the statement made is technically accurate. I don't think it helps their case much, because in this case Getty Images is arguing that their images were being copied by the model, and we found no examples of Getty images being copied in our paper. But I guess it's at least true that sometimes it does happen. Here's another example of a case citing our paper in a way that's not outright wrong, but where it probably doesn't help them much:
Academics are continuing to study generative AI models and their behavior. Recent academic research shows that the likelihood Plaintiffs’ or class members’ code would be emitted verbatim is only increasing. For instance the study, Quantifying Memorization Across Neural Language Models by Nicholas Carlini et al., tested multiple models by feeding prefixes of prompts based on training data into each model in order to compare the performance of models of different sizes to emit output that is identical to training data. ... Or as simply put by the study, “Bigger Models Memorize More.” [source]
This statement is technically accurate in some sense of the word. The larger models do memorize more data when trained in the same way. But this doesn't necessarily mean that as time goes on future models will memorize more data; maybe as time goes on people find ways to train smaller models that have equal utility, thus reducing costs to serve them, and also incidentally reducing the amount of memorization.
But also, what we were measuring is not what this court case was focused on. Our measurements were studying base, non-post-trained models. This case was talking instead about GitHub Copilot, which may or may not behave quite differently. We don't know, because we didn't measure this. Fortunately, I think the Court in this case did a good job of understanding the limitations of our study:
In addition, the Court is unpersuaded by Plaintiffs’ reliance on the Carlini Study. It bears emphasis that the Carlini Study is not exclusively focused on Codex or Copilot, and it does not concern Plaintiffs’ works. That alone limits its applicability. And further, as Defendant GitHub notes, the Carlini Study does nothing to “rehabilitate Plaintiffs’ own concession that, still, ‘more often,’ Copilot’s suggestions are ‘a modification.’” ECF No. 214-2 at 21 (quoting ECF No. 201 ¶ 108).
The Study “tested multiple models by feeding prefixes of prompts based on training data into each model in order to compare the performance of models of different sizes to emit output that is identical to training data.” ECF No. 201 ¶ 104. It determined that when models are “prompted appropriately, they will emit the memorized training data verbatim.” Id. (quoting Carlini Study). In regard to the GitHub Copilot model in particular, the Study concluded that it “rarely emits memorized code in benign situations, and most memorization occurs only when the model has been prompted with long code excerpts that are very similar to the training data.” Carlini Study at 6. To paraphrase Defendant GitHub, “Plaintiffs tried to [prompt Copilot] in their last complaint . . . to generate an identical copy of their code” and they were unable to do so. ECF No. 214-2 at 22 (emphasis omitted). Accordingly, Plaintiffs’ reliance on a Study that, at most, holds that Copilot may theoretically be prompted by a user to generate a match to someone else’s code is unpersuasive. [source]
I agree with the Court's interpretation of our work here. We show that it is possible models could memorize training data, and it is possible larger models could do it more. But it is not a silver bullet. Let me now again quote one final decision that I think gets it right:
DeviantArt asks me to review to the full content of one of the academic articles plaintiffs rely on, the Carlini Study, in particular the article's conclusion that for the 350,000 training images studied, only 109 output images were “near-copies” of the training images. DeviantArt argues that it is simply not plausible that LAION 1.4 can reproduce any of plaintiffs’ copyrighted works given that the set of training images Carlini selected were the “most-duplicated” examples, numbering in the millions of impressions in the datasets. Id. Plaintiffs’ reference to Carlini, however, is only one part of the allegations that help make plaintiffs’ allegations plausible regarding how these products operate and how “copies” of the plaintiffs’ registered works are captured in some form in the products. As noted above, it is not appropriate to rely on the defendants’ assertions regarding the method or sample size used by Carlini and their conclusions from it to foreclose plaintiffs’ claims; plaintiffs aggressively dispute the implications from the sample size and results of that study. [source]
Again, I think that the Court does a good job to understand the limitations of our study and how it may or may not apply to the case at hand. I'm glad that, at least so far, even if the lawyers have tried to use our work in a way beyond what it was intended for, the Court has been able to see clearly.
Recommended reading
My papers focus on the technical problem of memorization in machine learning models. This may provide some evidence that is relevant to specific legal questions, but is unlikely to be the best evidence for most cases. If you are arguing on behalf of some claim, the best thing that you can do is to actually go and collect your own evidence, or find some other paper that actually approaches this problem from a legal perspective.
If you feel like you must cite something academic, I'd encourage you to first read some of the papers a few of my co-authors have gone on to write without me. These papers actually try to consider the legal implications of machine learning and copyright directly. Katherine Lee, who helped lead several of the papers I mentioned above, wrote a massive 186 page report on this topic with A. Feder Cooper and James Grimmelmann. They also wrote a followup report discussing things in more detail. If you want to understand how memorization and copyright intersect, you should definitely be reading these papers.
Conclusion
I have my own personal opinions about how I would like copyright and machine learning to be treated. And many ML people I talk to also have their own thoughts on what they would like to happen. But what I think should happen doesn't matter; I'm not trained on this---neither on the legal side, nor on the societal impacts side. So you shouldn't care what opinions I have on this.
You (a hypothetical lawyer) probably are trained to think about the implications of laws like this, and so your opinion is probably more valuable than mine. But you should base your opinion based on what is true and what is false. If your legal opinion doesn't mesh with the facts of the world, that's on you. Fix your legal opinion.
Our work establishes some minimal facts that are true about the world. But the facts it establishes are fairly weak. Just about the only thing you can conclude from our work is that models, sometimes, output verbatim data they were trained on. This means that the data is, somewhere, somehow encoded in the model's parameters. But that's about all you can conclude.
Given these facts, there is plenty of room for legal debate. Is a model that only sometimes outputs verbatim text of training data a violation of copyright? The purpose of the model isn't to do this; does that matter? What if the objective function does encourage memorization? What if it didn't? If someone is responsible, is it the person who trained the model? the person who used it? the people who made the dataset? the person who served the model? Lawyers have argued about all of these aspects; all of these are fair game for debate.
But we should be having this legal debate based on the facts that are true, not the facts we wish were true.
There's also an RSS Feed if that's more of your thing.